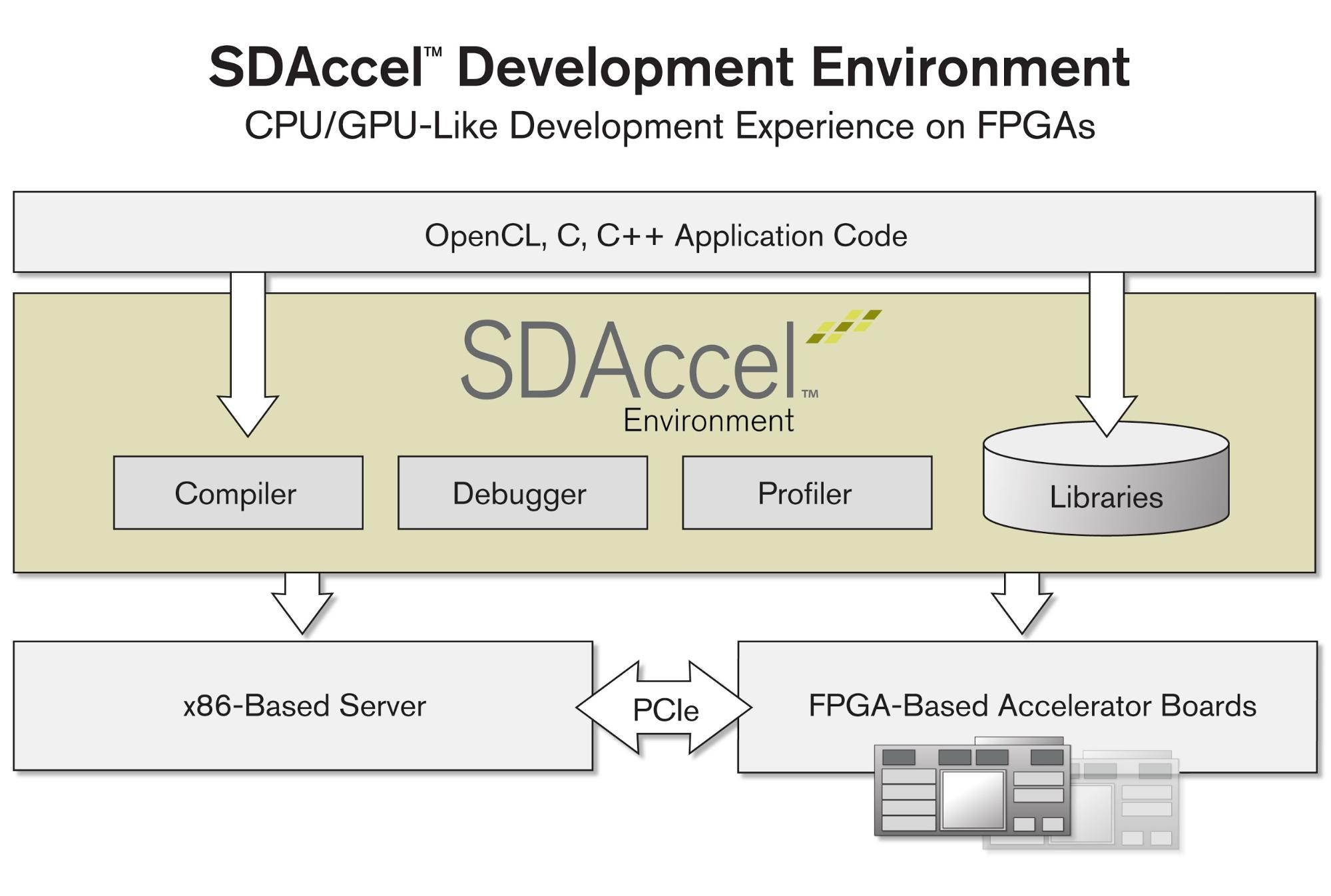

Fig 1. Xilinx SDAccel toolchain for FPGAs
Fig 2. Xilinx Kintex Ultra-scale FPGA accelerator board
Title: OpenCL-based Dense Stereo Matching and Depth Estimation algorithms on FPGA
Keywords: High level synthesis, OpenCL, Quasar
Promoters: prof. dr. ir. Bart Goossens (TELIN), prof. dr. ir. Erik D’Hollander (ELIS)
Problem statement:
In automotive applications (e.g., advanced driver assistance systems, self-driving cars), there is a high demand for efficient (i.e., power, computationally and cost-wise) parallel algorithms running on embedded platforms.
Within Ghent university we have vast experience on parallelization on GPUs. This has resulted in the development of our own programming language for heterogeneous hardware, called Quasar. This language automatically detects the parts that can run in parallel and transforms these parts to kernels suitable for GPU and multi-threaded CPU execution, allowing the user to write hardware agnostic code, significantly simplifying the development process, compared to traditional GPU programming languages such as CUDA and OpenCL. Internally, Quasar generates OpenCL/CUDA code and uses the OpenCL/CUDA runtimes.
According to a recent study [1], modern GPUs are outperformed by FPGAs by a factor 3x-4x in terms of performance/Watt for devices of the same cost. Moreover, compared to FPGAs, for GPUs it more is difficult to give hard execution time guarantees, which makes the use of GPUs in real-time applications sometimes problematic. Because of the popularity of GPU programming languages, since recently, Xilinx also supports the OpenCL programming model for their FPGAs (in their SDAccel product). However, due to architectural differences between FPGAs and GPUs, even with OpenCL, some programming challenges for FPGAs still remain: OpenCL kernels are to be annotated with vendor-specific pragmas/attributes that indicate how the hardware mapping (synthesis) should be performed. During the optimization of the hardware synthesis of an algorithm, the programmer often needs to provide and test a lot of such pragmas/attributes.
Fig 1. Xilinx SDAccel toolchain for FPGAs | Fig 2. Xilinx Kintex Ultra-scale FPGA accelerator board |
Goal:
In this thesis, we will design and investigate code transformations that aid the mapping of code from a high-level programming language (e.g., Quasar) to Xilinx SDAccel (OpenCL) with pragmas/attributes. Improving the programmability of FPGAs brings several advantages: 1) application experts that are not hardware specialists can easily program FPGAs, 2) algorithms can be designed that can be executed on CPU, GPU and FPGA in a truly heterogeneous way and 3) it becomes possible to combine the advantages of CPUs, GPUs and FPGAs for specific processing tasks.
We will focus on a dense stereo matching and depth estimation algorithm, used within automotive applications, and design and develop an efficient OpenCL implementation for the Xilinx SDAccel platform. Next, we will look at the differences between the high-level programming code and the OpenCL implementation and investigate how the mapping between both can be facilitated by means of high-level symbolic code transformations.
Hence, the primary goal of the thesis is to design code transformations that improve the programmability of FPGAs via SDAccel and Quasar, in such a way that the code transformations can also be used for other image processing algorithms. In a later phase of the thesis, we will investigate at heterogeneous execution on both FPGA and the CPU (or GPU) and determine performance trade-offs between the architectures.
Fig 3. Vivado HLS SDAccel/OpenCL development environment |
Extra info:
This master thesis is in collaboration with Xilinx, with headquarters in San José (California, USA) and in Dublin (Ireland) and Singapore. After an interview of Xilinx with the candidate, there is possibility to combine this thesis with an internship at Xilinx in either San José or Dublin (note: the internship cannot overlap with the duration of the thesis, so the internship should be best taken during the summer holidays).
References:
